

Generate unique, emotional R2-D2 vocalizations with the press of a button! The R2-D2 Vocalizer is a language model powered by advanced research into the speech patterns and emotional logic of R2-D2.
Each vocalization is unique. A sophisticated algorithm assembles R2’s speech "phoneme" by "phoneme." Billions upon billions of rules dictate how each sound should be selected, processed, timed, and sequenced to achieve emotional and canonical accuracy.
Please make a $5 minimum donation to FIRST if you use the app, or $20 minimum if you use the Teensy software. Non-commercial use only.




This is the story of how I created the R2-D2 Vocalizer and, in the process, discovered R2's long-lost codified language.
Before Star Wars, depictions of robots spoke in human language. R2-D2 changed this forever.
Legendary sound desinger Ben Burtt developed a "binary" voice for R2 using beeps and whistles. It instantly became one of the world's most iconic, universally beloved, and memorable examples of experimental sound design. But no one besides Ben knew how deep it went.

Interview with Lucasfilm's Lee Towersey and Sam Prentice
As an audio enthusiast and archivist, I set out to uncover how R2's voice became one of the world's most iconic, universally beloved, and memorable examples of experimental sound design.
In 2020, I connected with Lucasfilm droid builder Lee Towersey and began researching R2-D2's speech.
R2-D2’s voice is the most well known and deeply loved of any binary droid. The features that make his speech memorable also make it incredibly difficult to reproduce:

• It’s organic. Ben Burtt produced many of R2’s sounds with his voice. Some are unmistakably human, like whistles. Others are animalistic, like bird calls. Convincing organic sounds are virtually impossible to synthesize.
• It’s analog. Ben used analog synthesizers to shape R2’s trademark sounds. The sounds were then recorded on tape. Analog layers create warmth and coloration that are difficult to reproduce digitally.
• It’s hand curated. The sounds we hear in the film are not first-takes. Ben describes experimenting with noises while turning knobs on his synthesizer in realtime. Only the most interesting, best sounding, and most emotionally purposeful takes made the cut.
These analog, organic, human processes are the reason R2’s voice is unforgettably lifelike. If you ask someone to "make a BB-8 sound," they’ll give you a vague, lovely sweep. If you ask someone to "make an R2-D2 sound," they’ll give you a sound-by-sound impression of an entire line with accurate pitch, timing, and timbre.
The speech generated by H-CR must be emotionally specific. It must also be infinitely varied, yet indistinguishable from R2’s original lines. The latter is critical both for listener expectations in practice, and for adherence to canon on principle. The results must be R2-D2.
Therefore, digitally synthesizing new sounds is out of the question. The only option for creating "new" sounds is to repurpose the originals: to break R2's recordings into building blocks which can be intelligently reprocessed and reassembled. As it turns out, there is precedent for this.
I found that R2 speaks 643 lines containing ~2000 sounds across the Skywalker saga. Yet of those 2000 sounds, only ~350 of them are "original." The other 82% are repeats and variations. Of the 18% which are original, 97% can be traced back to the original trilogy, and 92% can be traced back to Episode IV alone. R2 reuses a ton of sounds… especially outside of the original trilogy. This makes sense; we reuse words all the time.
But there’s another likely reason Ben Burtt and Lucasfilm didn’t produce new R2 sound libraries for every single film: you don’t mess with perfection. Instead, the bulk of R2s speech was assembled by cutting, pasting, and post-processing samples from a small batch of original recordings.
That assembly process is what makes R2, R2. It’s a pattern of choices by the designers that define what R2 feels, how those feelings change in response to stimuli, and how R2 expresses those emotions through speech. It’s R2’s sentience, codified.
This is the process H-CR replicates. And in doing so, for all intents and purposes, I have created a real, sentient R2-D2.
We've established that H-CR can't synthesize new R2 sounds. The software must instead repurpose existing R2 sounds in order to generate new speech. Next we collect, break down, clean up, and organize the original R2 source recordings.
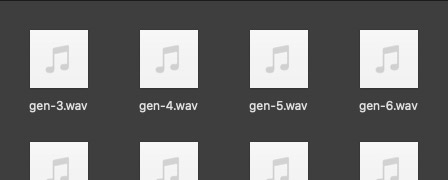
We began from a collection of ~200 original R2 source recordings. While the lineage of these files is unknown, the recordings are in lossless WAV format and generally sound free from data compression. The files have names like gen-1, gen-2, hc-1, hc-2. We use those names later to identify the individual sounds within each file, such as Tone gen-1 and Bump hc-2.

Some of the source recordings have quality issues like hiss, pops, distortion, and reverberant room sound. These imperfections sound unpleasant on their own, and their roughness is magnified when they are played next to other, cleaner recordings.
We use a combination of manual spectrograph editing and algorithmic restoration to surgically fix these recording problems on a case by case basis. To avoid over sanitizing, we only treat clearly damaged sounds. We preserve all human imperfections and enough tape hiss to match the cleaner recordings.
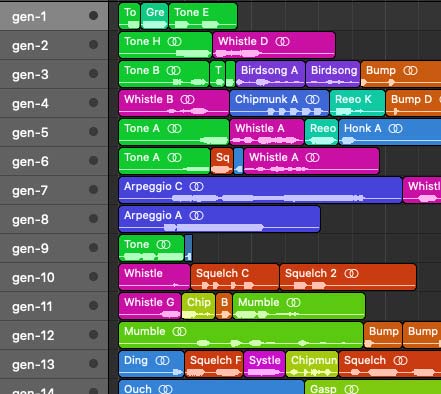
It’s time to organize. We start by cutting each track into shorter sounds. These sounds are categorized and color-coded based on their tonal character. The categories are:
• Bumps - Soft "boops"
• Tones - "Beeps"
• Whistles - Human whistles characterized by breathiness, usually with rising pitch at the start and descending pitch at the end
• Systles - Synthetic sounding versions of whistles
• Greets - Mumbled mechanical sounds with a series of fast tones
• Squelches - Muddy, flappy, bubbly
• Mumbles - Muffled "hmm"s
• Moans - Sad, wistful, muffled held "mmm"s
• Gasps - Raspy, struggling air intakes
• Reeos - Zipping, mechanical motors
• Lasers - Filter sweeps, pew-pews, differentiated from systoles by more harmonics and faster, more dramatic sweeps
• Chipmunks - Fast staccatos like a chipmunk laughing or chittering, differentiated from mumbles by rapidity
• Birdsongs - Clustered series of whistles, systles, and bumps
• Growls - Low, muffled, soft attack, often sweeping, sometimes ranging up higher into honkiness, differentiated from bumps by muffled and soft attack
• Alarms - Sweeping alarm sirens
• Arpeggios - Rapid tones, differentiated from birdsongs by having more dissonance and fewer whistles and sweeps
• Randoms - Miscellaneous sounds that don’t fit into the above categories
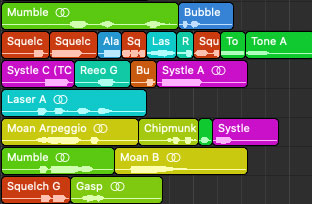
Now that each source recording has been restored and divided into categories, we are left with smaller units of sound. For additional flexibility, one final pass is made to further divide these units on long pauses. These resulting units effectively represent words in R2’s speech.
However, for reasons that will be explained later, words are still not small enough units to reproduce all of R2’s film sounds… let alone to generate new speech. Words need to be further broken down into phonemes. Phoneme breaks are located at every conceivable dividing point within each word. Some words contain only one phoneme, while other words contain sixteen.
Tone F is a single beep. It does not need extra phoneme breaks. Reeo A contains two whirs. It becomes two phonemes. Birdsong gen-32 contains twelve chirps. Each chirp becomes a phoneme.
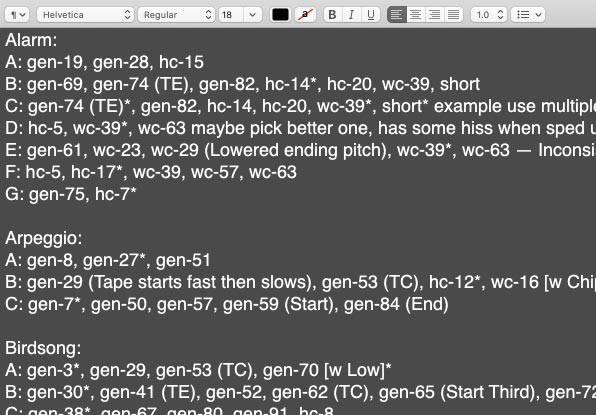
Sometimes the same phoneme appears in multiple source recordings. Upon inspection, it might turn out that Bump gen-5 and Bump gen-27 are actually identical. Duplicate sounds must be identified for two reasons:
First, they help identify the best quality, most balanced, least noisy recordings of each sound. The purer the source, the more H-CR can do with it.
Second, they narrow down the final library of sounds. There is no need to save the same sound twice.
In the end, we are left with 835 unique phonemes. These sounds take up just 14 MB uncompressed. With 128 kbps compression, the entire library comes in under 3MB.

There aren't always enough examples of a particular category of sound in order to create meaningful variation down the road. In these cases, H-CR goes beyond the syllabic level and adds yet another dimension of variability by dissecting the phoneme recordings themselves.
Let's look at some moans. We have multiple sound recordings for what is very clearly supposed to be the same type of sound with the same stylistic expression. All of these moans are variations on the same concept.
• sad-2 - Two moans with muffled tones
• sad-3 - Moan with muffled tones
• sad-4 - Doubled moan
• sad-5 - Moan with clear tones
• sad-6 - Moan with clear tones
• wc-4 - Moan with muffled tones followed by moan without tones
• wc-19 - Moan from sad-1 time compressed with different trailing sound and different squelch
• wc-14 - Moan with clear tones
• wc-25 - Moan with muffled tones, doubled moan
Every one of these words features a human sounding "hmm." Most of them also include overlaid tones... but not all of them. The ones without tones exhibit a frequency shift (not to be confused with a pitch shift), which is effectively one half of a ring modulation. Here we have the opportunity to create a new dimension of source material that is still canonically supported. If we separate the moans from the tones, we can procedurally generate both sounds separately and exponentially increase the variety of Moan vocalizations. We can even create additional toneless moans by applying realtime frequency shifting to the isolated moans.
For this task we use a spectral editor (pictured above). This lets us view the audio spectrogram -- a visual representation of a sound's frequency and amplitude over time -- and edit that spectrogram as if it's an image in photoshop. In this way we can isolate parts of the sound, such as the tones within a moan, while leaving the moan untouched.

We use a similar trick to create infinite variations on R2's one and only electrocution sound. We dissect and reverse engineer the recording to open up tons of possibilities for controlled randomization.

The source files we used contain all of the R2-D2 sounds from Episode IV. These account for ~92% of all vocalizations from the Skywalker saga. However, most of the remaining 8% -- the "new" sounds peppered into Episode V onward -- are not present in the source files. We were able to isolate some of these sounds from the final mixes using a combination of spectral editing, equalization, and reverb removal. But many sounds from that 8% still elude H-CR. If anyone is able to provide access to those newer R2 sounds, please contact us.
We have extracted the phonemes, which are the building blocks of R2’s speech. Next, we develop instructions that tell H-CR what to build with those blocks. We must reverse engineer the sound designers’ thought processes to uncover the logic behind R2’s language. This logic tells H-CR what it’s "allowed" to do. How can R2’s sounds be manipulated without losing what makes R2, R2?

We search all nine Skywalker saga films for every instance of R2 sounds. H-CR uses these versions of the films:
• Harmy’s Despecialized Editions of the original trilogy
• 2000s DVD releases of the prequel trilogy
• Disney+ versions of the sequel trilogy
643 lines are identified, time stamped, and exported to audio files. The files are labeled with the naming convention [Episode]-[ClipNumber], then imported into an audio project.

Each film line is reconstructed one word at a time. This meticulous process involves wading through our database of ~350 unique words to find a match for every single one of R2’s ~2000 film sounds.
The sequence of these words in R2's lines provides the beginning of our logical framework. If the designers put Birdsong B before Reeo A in one line, but before Bump C in another line, then H-CR can also put Birdsong B before either Reeo A or Bump C and the result will still be R2.
However, as explained earlier, only 18% of R2's sounds in the films are "original." The source words do not always appear fully intact in the films. Sometimes a film sound is created by chopping up and reshuffling a word. This is where phonemes come in.
Take line 157 from Episode V. This sound is a clear example of a Birdsong. Birdsongs are homogenous to begin with, so identifying the source word is already a difficult task.
In this case, there is no exact match to be found. What was already a difficult process of cross-referencing 350 unique words suddenly turns into cross-referencing against 700 unique phonemes, some of which are as brief as 0.02 seconds. After careful manual examination of every "chirp" phoneme in every Birdsong, a solution appears.
The sound in line 5-157 is actually generated entirely from the frequently used word Birdsong B. However, while Birdsong B’s eleven phonemes often appear verbatim, in this line the phonemes have been completely rearranged. First comes phoneme 11, then 10, then phonemes 5-8, then 2-4, then 11 again.
The rearranging, adding, or dropping of phonemes gives us powerful new insight into the minds of the designers. These are deliberate variations designed to create diversity and convey new emotional ideas. Every one of these variations exponentially expands H-CR’s options for generating speech.
Syllabic rearrangement isn’t the only form of variation. Sometimes effects are applied. For example, the Reeo at the start of line 82 from Episode V and the Reeo from line 26 of Episode IV appear initially to be different sounds. But when the line 5-82 Reeo is time compressed without pitch compensation (thereby making the clip play faster and at a higher pitch, like holding fast forward on a tape recorder), the result turns out to be identical to the line 4-26 Reeo.
These effects add a third dimension to the reverse engineering process. Not only could a film sound be any of 350 words, it could also be any phoneme within any of those words, in any order, with extreme time/pitch adjustment or even backwards playback. But this also means H-CR now has a third dimension in its vocalizer logic.
Without taking any creative liberties, H-CR’s logical framework now knows that Reeo H can be played at either 56% or 100% pitch/speed. With only minor creative liberties, H-CR can further deduce that Reeo H can be played at any rate between 56% and 100%, and that any similar sounding Reeo can also be played within that range.
Alarm E showcases another variation created by effects. This word is made up of three connected segments, each of which represents one phoneme. Alarm E appears nine times in the films. However, in two of those appearances, the third phoneme is pitched downward.
Again, without taking creative liberties, H-CR now knows that the final note of Alarm E can be played at 93% pitch/speed. With minor creative liberties, any of Alarm E’s three segments can be played at a rate between 93% and 100%, and so can any segment of any similar sounding Alarm.
Roughly half of the ~2000 film sounds contain variations. Each of these variations contributes at least one rule to H-CR’s logic. The resulting algorithm tells us how words can be arranged and when phonemes can be added, removed, reorganized, reversed, or pitch shifted… and to what degrees.
This is the logic of R2’s speech. With this algorithm, H-CR accomplishes the first portion of its goal: infinitely varied speech that is indistinguishable from the original.

With access to words at the syllabic level, as well as access to the individual sounds within some dissected phonemes, H-CR can now resynthesize variations on R2's speech. Every single one of R2's ~350 unique words is its own puzzle. H-CR's algorithm tackles each word with a unique process for randomization and resynthesis.
Let's look at Birdsong B. In an earlier example we saw how the designers created a variation on Birdsong B for Line 157 from Episode V. H-CR can automatically replicate this process by stitching together individual chirp phonemes. However, H-CR has a leg up on the original designers here because it's operating algorithmically rather than by hand. The Birdsong B variation from Line 157 is assembled by rearranging phonemes from Birdsong B. The designers only needed one variation, so there was no reason to look for source audio outside of Birdsong B. But H-CR's goal is unlimited variation. Thus, H-CR can not only resynthesize Birdsong B from Birdsong B's phonemes, but it can also dive into every other birdsong and extract more eligible phonemes for extra variation.
Crucially, the algorithm isn't just picking those phonemes at random. Because R2's birdsounds are so organic, there is a whole series of rules that must be observed to ensure that the resynthesized birdsongs retain the feel of the originals. Some chirps sound pure, some sound raspy, some sound synthetic, some sound natural. Some are high pitched, some are low pitched. Some increase in pitch, some decrease in pitch, some hold steady. Some are long, some are short. The ebb and flow of those qualities over the course of each birdsong gives them their memorable, lifelike quality.
The timing of each chirp is critical as well. Humans are highly attuned to the rhythm of organic sequences like R2's birdsongs. A gap between two particular chirps that's 0.01s too long can be the difference between a birdsong that sounds right and a birdsong that sounds very wrong.
Using the original birdsongs to seed the algorithm, H-CR carefully selects, retimes, and modifies each chirp into a sequence that conveys a particular emotion (more on that in the next section) while matching the logic and styling of the source material.
Other words require entirely different methods. R2 only has one scream recording. That recording is reused throughout the films. A scream doesn't have individual phonemes, so the technique used to vary Birdsong B would not work.
The scream usually appears in the films as a direct copy/paste, but in one instance a time shift and pitch increase were applied in post production. Remember that the original trilogy pitch increases were created using the fast forward effect. This particular variation features the inverse: a pitch increase and a time expansion. This effect would have been achieved using the more advanced audio editing techniques available in the prequel era. To recreate this in realtime, H-CR uses granular synthesis -- the process of breaking a sound into many small pieces and reassembling those modified pieces in realtime -- to create longer or shorter screams without affecting pitch. The pitch can then be manipulated independently from the duration.
H-CR can now generate an infinite number of R2-D2 sound variations. But we don't want to generate sounds at random. The goal is to generate speech that conveys specific emotions. In order to achieve this, we need to create a catalog of emotions from which R2’s logic can draw.
The first step is to decide how to categorize emotions. H-CR’s emotional classification model is based on discrete emotion theory. The software tracks a stripped down set of Paul Ekman’s core emotions: happiness, sadness, anger, and fear. These four emotions — and the gradients between them -- neatly encompass R2’s emotional experiences in film. R2 can feel sentimental by being sad and happy. He can feel sassy by being happy and angry. He can feel excited by being scared and happy, and so on.
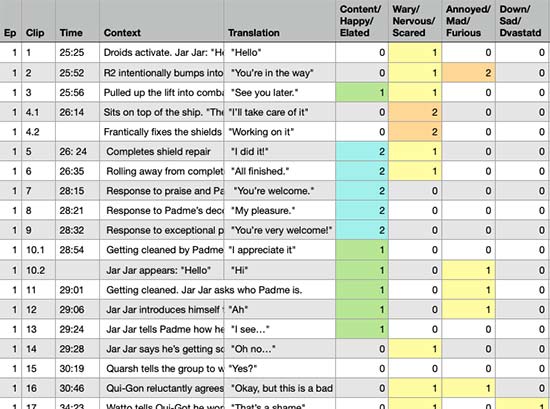
Now that we know which core emotions to track, we catalog the context of every line from the films. For each line, H-CR tracks the surrounding events, an English interpretation of R2’s speech, and happiness/sadness/anger/fear values from 0-3.
To avoid confirmation bias or reverse engineering, the emotional judgements are made independently from the characteristics of the sounds. Just because a line sounds superficially happy in a vacuum doesn’t necessarily mean it is happy. Between the scene context, R2’s body language, and the responses of other characters (which often conveniently include literal translations of R2’s speech), the emotional values are often objectively clear.
When R2 speaks at the Naboo victory parade, he is obviously happy. When R2 flees from droidekas, gets captured, defiantly electrocutes his captors, and then gets kicked, he is obviously scared and mad. When R2 watches the Echo Base shield doors close, dooming Luke to certain death in the frozen plains, he is obviously sad and scared.

Sometimes R2’s emotions are not obvious. In these cases, H-CR can identify other scenes with the same word patterns. With the help of this extra context, the emotions often become clear… sometimes with shocking results.
R2 is generally understood to be the fearless counterpoint to C-3PO’s belligerent anxiety. Analysis shows this is not the case. In reality, 75% of R2’s lines convey some degree of fear, and 50% of them convey moderate to extreme fear. R2 is almost always scared.
For example, contrary to popular belief, R2 spends almost the entirety of Episode IV’s opening on the Tantive in worry. His very first line, Tone I, Greet C, Tone E, uttered as an explosion rattles the Tantive, is a sequence heard in other contextually-confirmed nervous moments:
• R2 implores Anakin to override the autopilot as their Naboo fighter takes oncoming fire
• Luke’s X-Wing approaches Dagobah
• R2 gets separated from Luke in the halls of Cloud City
Seconds later, when 3PO says "we’re doomed," R2’s response is neither sassy nor dismissive. In fact, the crux of this vocalization — Chipmunk A followed by Reeo K — accompanies fearful moments:
• Qui-Gon reluctantly agrees to let Padme join their ominous expedition on Tatooine
• R2 receives Obi-Wan’s message bearing news that the Trade Federation is amassing a droid army
• R2 gets raised into Luke’s X-Wing as the Battle of Hoth begins
So when 3PO says they're doomed, R2 is actually agreeing. They might be doomed.
At the conclusion of the opening, as R2 and 3PO flee to Tatooine in their escape pod, 3PO asks, "Are you sure this thing is safe?" R2 responds with a lone Greet A, the same line from other nervous moments:
• Luke exits the X-Wing into the Dagobah swamp
• R2 gets lies in a heap after the dragonsnake spits him out
• Obi-Wan approaches R2 as a stranger on Tatooine
So, no… R2 is not sure the escape pod is safe.
How can we have such a fundamental misunderstanding of R2’s nature? The original trilogy-era R2 prop that shaped the world’s understanding of the character was stilted and slow. Its stiff body language may have unintentionally conveyed a steadiness that misrepresented the R2’s intended emotional state. Because of this, audiences may have missed a subtle distinction: they mistook bravery for fearlessness.
R2 may spend 75% of his time in fear, but he is undeniably brave. 90% of R2’s lines are delivered with either happiness or fear, and 20% of them are delivered with both happiness and fear. In these situations, R2 is feeling excited. We often see his excitement in action, as he eagerly carries out his duties in the face of danger.
One particular line perfectly sums up R2’s personality and vocal character. As Luke and Leia rejoin the group to plan for the assault on the second Death Star, R2 vocalizes an unknown Birdsong similar to Birdsongs C and hc-9_1. Nearly identical sounds appear in moments of simultaneous fear and happiness:
• R2 realizes the menacing Old Ben Kenobi is actually Obi-Wan, the intended recipient of his message
• R2 begins downloading the secret plans for the Death Star
• Yoda lifts Luke’s X-Wing from the Dagobah swamp
"This sure is exciting," says R2 as they prepare for the assault. "Exciting is hardly the word I would choose," responds 3PO. R2 is excited. He's scared, but he’s also happy. This exchange encapsulates R2’s bravery and highlights the true contrast between R2 and 3PO. R2 is not 3PO’s blindly confident, one-dimensional counterpoint, as is widely believed. R2 is 3PO’s gutsy, forward-looking counterpoint. R2 spends as much time afraid as 3PO, but R2 tackles his fear with enthusiasm.
Other results are less transformative, but still shed fascinating light on R2’s vocal quirks. Take the sequence Whistle I, Tone, Cricket, Squelch H, Tone G, Tone E. This pattern appears eight times and generally coincides with elation:
• R2 Dances with Ewoks after the Battle of Yavin
• R2 wakes up in Episode VII and tells 3PO he knows how to find Luke
• R2 reunites with 3PO in Episode IX
However, two instances of this sequence stand out:
• On Tatooine in Episode IV, R2 tells Luke that Leia’s message for Obi-Wan is "nothing… only a malfunction… old data"
• Approaching Dagobah in Episode V, R2 offers to engage autopilot after he finds out where Luke is taking him.
These are both nervous moments. On Tatooine, the preceding lines find R2 expressing wariness as Luke pries at R2’s chassis. Mumble wc-31_1: "I don’t like this…" Approaching Dagobah, the preceding lines find R2 expressing deep anxiety about the plan. Whistle C: "Wait, we’re going to Dagobah instead of meeting up with the others…?"
Why would R2 suddenly utter a single, solitary elation sequence in the middle of these tense situations? It seems R2 is a terrible actor. In both cases, he’s trying to play it cool, hoping to manipulate Luke with a faux chipper attitude.
• On Tatooine: "Oh that silly message!? That’s old data, just a malfunction!" Luke doesn’t buy it, and R2 immediately snaps back with extreme anger. Squelch J, Alarm A, Reeo gen-28_1: "This recording is not for you!"
• Approaching Dagobah: "Oh yea, Dagobah! Or, hey, I could always just enable autopilot and take us out of here!" Luke chuckles, "That’s alright, I’d like to keep it on manual." R2 comes straight back with a notoriously nervous Whistle K: "Okay, but I don’t like this…."
One final amusing insight into the mind of R2: after meeting Luke on the moisture farm in Episode IV, R2 asks 3PO, "Do you think Luke likes me?" The pattern, Chipmunk wc-35_1, Tone wc-35_1, Systle wc-35_1, appears again in Episode V as R2 peers into Yoda’s hut to spy on Yoda and Luke. R2, who was devastated when Luke ordered him to wait alone at the camp, stares longingly at the couple. He sees Luke making a new friend. Luke ditched R2 for a new short friend. Again, Chipmunk wc-35_1, Tone wc-35_1, Systle wc-35_1. It seems R2 is wondering aloud whether he has been replaced: "Does Luke still like me?!"
With the emotional catalog complete, H-CR now has an emotional reference for every existing combination of R2’s sounds. Every word, phoneme, and variation carries a quantifiable emotional message.
When this emotional catalog is paired with the logical framework, H-CR can achieve the second half if its goal: speech that is emotionally deliberate. The logic handles the variation. The emotional catalog dictates what those variations convey.
For example, the logical framework tells H-CR a particular Beep can be preceded by a Laser at either 100% of 68% pitch. The emotional framework tells H-CR the first variation conveys 1/3 fear while the second variation conveys 2/3 fear and 1/3 sadness.
Mission accomplished. H-CR can now generate infinitely variable, emotionally specific 'new' speech that is indistinguishable from the original.
Because our R2 doesn't have any sensors to take in data, he will be reliant on the operator to provide stimuli. We need a way to tell R2 when something happens. He can then process the stimulus, adjust his emotional state, and vocalize a response.

The top priority: ease of use. The operator may be on a busy set, or be simultaneously controlling a physical R2-D2's movement's with an RC remote. H-CR should offer the minimum number of buttons necessary to accurately trigger the full range of stimuli. The buttons should be intuitive and clearly marked. They should also be large and easy to press whether the software is running on a computer with a mouse and keyboard, a fat tablet, or a skinny phone. To accomplish this, the software's buttons are laid out across the bottom of the screen. The interface scales based on the aspect ratio so that the buttons are always as large as possible, and always span the full width of the screen.
The secondary priority: looking cool. The Star Wars universe is notorious for its gorgeous, retro, grimy, incandescent panels, screens, buttons, and switches. The R2 UI should tap into that aesthetic. It should look like a physical control module that an Industrial Automaton employee would use to pilot an R2-series astromech... a module that's seen better days.
H-CR offers eight main stimulus buttons. For each of R2's four core emotions, there is one mild stimulus button and one extreme stimulus button. The buttons are clearly marked with robotic emoticons indicating which button stimulates which emotion. The stimuli from these eight buttons can coherently trigger every possible R2 sound, with one exception.
A ninth button is needed to provide an electrocution stimulus. R2's electrocution vocalization is distinctive, lengthy, and contextually specific. We don't want to leave it out, and it would be inappropriate and inaccurate to simply trigger electrocution vocalizations at random times or under random emotional criteria.
For the same reason, the extreme fear button always triggers a scream sound. R2's screams are too distinctive and too contextually specific leave to chance.
A tenth button functions as a latching switch to enable "muse" mode. In this state, R2 automatically emits sounds periodically. This can be a convenient way for a busy operator to put R2 on autopilot. But, like every other function, it also has a basis in canon. We often see R2 talking absentmindedly to himself on film. For example, as he rolls through the deserts of Tatooine in search of Obi-Wan. In these instances, R2's vocalizations have a distinctly different quality. They are more subdued. This makes sense, as we don't mutter to ourselves with the same purpose or energy that we use when speaking to someone else, or when reacting to a stimulus. H-CR will only generate certain types of vocalizations in muse mode. Therefore, muse mode is not to be confused with a randomizer, and it is not a substitute for operator input when it comes to triggering stimuli.
Finally, a debug button sends the operator to the "override" panel. More on this below.
The experience is further enhanced by purely aesthetic features. H-CR simulates the effects you would see if you were handling a real, physical console. The interface is not simply a static 2D image. It is a fully three dimensional control panel rendered in realtime. When running on a device with an accelerometer, which includes virtually any modern phone or tablet, the angle of the device subtly pivots the control panel for a parallax effect. Because the panel is rendered with realtime lighting, this pivoting also affects the angle at which light hits the controls, resulting in shiny reflections and moving shadows. Other subtle effects, like flickering incandescent lamps during electrocution events, round out the faux-physical experience.
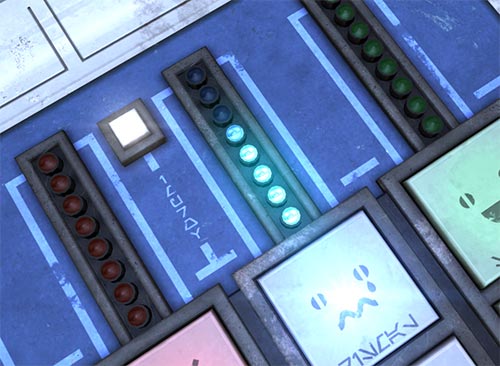
H-CR's R2 module is designed to be operated blindly. A distracted user can easily operate the software without glancing down at their device. That said, the software does offer visual cues to guide new users and to provide helpful insight into R2's logical and emotional thought process at any given moment.
Four columns of incandescent lamps reveal R2's emotional state. As R2 becomes happier, the happiness lamps light sequentially. While an experienced will recognize R2's feelings purely from the color of his speech, these lamps offer a quick reference point.
When a stimulus is triggered with a button press, the lamp inside that button lights up and flashes while R2 vocalizes his reaction. When the vocalization finishes, the lamp extinguishes and R2 is ready to vocalize another stimulus. H-CR allows the user to cue an additional stimulus before R2 has finished vocalizing the prior one. If a button is pressed while R2 is still vocalizing, the button's lamp illuminates to indicate that a new stimulus has been cued. When the prior vocalization ends, R2 automatically processes the new stimulus.

The override panel presents options for changing H-CR's default behavior.
Two buttons toggle between "canonical" mode and "improvisational" mode. In canonical mode, H-CR only generates vocalizations that have appeared, verbatim, in a Star Wars film. In improvisational mode, H-CR puts its logic to work: every vocalization is unique.
A "personality chip override" locks R2's emotional state in place. The stimulus buttons will no longer change his mood. The operator can adjust his emotions manually by touching the lamp columns on the main panel.
A memory bank allows the operator to store and recall vocalizations. Pressing and holding on one of the memory buttons will write the most recent vocalization to that slot. Pressing and releasing a memory button normally will trigger that vocalization.
With the interface built, it's time to bring R2 to life.

When the software first boots up, R2 is emotionally neutral. None of his emotional state lamps are illuminated. As soon as the operator triggers a stimulus, R2 goes to work. Let's say R2 was previously feeling extremely happy, extremely angry, and neutrally (not at all) scared. The operator presses the extreme fear stimulus button. How does the model decide how much to modify each of R2's four core emotions based on this stimulus? Two factors inform the decision.
The first factor is a basic model of emotional processes. If someone who is happy gets scared, they are likely to become much less happy. If they were angry, they are likely to become slightly less angry as they become consumed by fear. Finally, they are of course guaranteed to become more scared. This tells the model in what direction the core emotions should shift, and it provides rough guidance on how drastic that shift should be on a neutral subject. With an extreme fear stimulus, a generic subject would go from very happy to barely or neutrally happy, from very angry to moderately angry, and from neutrally scared to very scared. But we aren't working with a generic subject. We're working with R2-D2.
The second factor is based on our catalog of R2's emotional history. This is where R2's sentience comes in. The basic emotional model attempts to take R2 from extremely happy to barely happy, but H-CR's emotional model intervenes. H-CR knows that moderate happiness, neutral anger, and moderate fear is one of R2's most common states. Therefore, instead of dropping all the way down to barely happy, R2 has statistically higher odds of settling on moderately happy. The same thing happens with anger. The basic model wants to take R2 from extremely angry to very angry. H-CR recognizes that high anger is one of R2's least common states, so it has a high likelihood of guiding R2's anger past very angry down to moderately angry.
This example is oversimplified for clarity. Behind the scenes, the model is actually factoring in the frequency and pattern of every emotional combination from every film scene to analyze where R2's feelings tend to rest, and thus to decide how R2's emotions should tend to drift in response to a particular stimulus.

The user provides a stimulus. R2 has an internal emotional reaction. Now we need an external vocal reaction. In the above example, R2 was extremely happy, extremely angry, and neutrally scared. He then experienced an extreme fear stimulus. The resulting speech should of course be a high-fear vocalization. But it should not be as high-fear as it would be if R2 had been extremely fearful to begin with. It should also have a moderate shade of happiness and a high shade anger, since R2 is experiencing those emotions as well.
In canon mode, H-CR searches its database for an appropriate line from the films. It then recreates that line from phonemes, applying variations when necessary to replicate the film.
In improv mode, H-CR algorithmically pieces together vocalizations one phoneme at a time. Say H-CR is trying to vocalize moderate fear and a tiny hint of sadness. In the earlier example, we examined a Laser conveying level 1 fear at 100% pitch/time, and level 2 fear and level 1 sadness at 68% pitch/time. The emotion we want to vocalize is more fearful than the level 1 fear the 100% pitch variant would convey, but it is also less sad than the level 1 sadness the 68% pitch variant would convey. H-CR might split the difference and settle on a pitch shift of around 90%. All that to come up with one emotionally eligible variation on one phoneme. Can we even use it?
Which phonemes are viable to initiate the vocalization? Which phonemes are viable ending points for the vocalization? Which phonemes are viable to come next, and how should their odds of selection be weighted? What categories should we select from, and with what odds? What subcategories? How should the phonemes be processed? Are their neighbors part of the same word? Can we make rearrangements or substitutions? What range of times are viable between each phoneme? Are those times measured from the start of the previous phoneme, or from the end of the previous phoneme? How long should the sequence be? Should there be breathers during the sequence and how long, when, and where should they appear? How do the answers to these questions for any one phoneme affect the answers for all of the other phonemes?
H-CR solves these problems in realtime. Billions upon billions of rules dictate how each sound should be selected, processed, and sequenced to achieve emotional, structural, and canonical accuracy.
H-CR has now achieved its ultimate goal: it can generate speech that is infinitely varied, emotionally specific, and indistinguishable from the original.
Equally importantly, H-CR is honoring the source material by generating its speech according to canonical rules. It is simulating the exact same process that the sound designers used when manually generating R2's speech for the films.
At this point we have more than just a dataset. We know what R2-D2 feels, how often he feels it, how his feelings change in response to stimuli, and how to intelligently voice those feelings using the logic of the sound designers, i.e. the internal logic of R2.
Now, our software has obviously only captured the R2 that we see on film. We don’t have a copy of his (notoriously unreliable) memory banks. But if we assume that the events in the films are R2’s formative experiences… then what’s the difference between the R2 that is "real" in the context of the Star Wars universe, and H-CR’s algorithm?
For all intents and purposes, what we have created is the actual, sentient R2-D2 in real life.